There are various formats for a dataset, .csv, .json, .xlsx, etc. The dataset can be stored in different places, on your local machine, or sometimes online. Many of the Python libraries are bundled with data set(s). One can install and load/import data sets in Python. For example, the vega_datasets is a Python library that contains some popular data sets.
# install vega datasets pip install vega_datasets
After successful installation of the vega_datasets library, one needs to import and load the data.
from vega_datasets import data iris = data.iris()
Now the datasets bundled in vega_datasets are locally available and one can readily access them without an internet connection. One can see the list of available data sets in the vega_datasets library.

Getting Data Set Information in Python
Since the iris data set is assigned to the variable iris. Now one can perform different computations on this variable.
# unique observations in iris iris.species.unique() # identifying missing observations in the data set iris.isna().any()

# checking the data types of variables in the data set iris.dtypes
Computing Statistics in Python
After checking some information and cleaning the data, one can perform different statistics on the data. For example,
# Descriptive Statistics iris.describe()
If a variable is not required for further computations, one can drop the variable and may create a new data set. For example, from the iris data set, if a “species” variable is not required, one can omit the variable and may create a new data set.
# data = iris.drop(['species'], axis = 1)
The argument axis=1 refers to the columns of a data frame or a series and axis=0 refers to the rows of a data frame or a series.
Reading Online Data Sets in Python
Note that one can also read the data from a URL. For example,
URL = "https://s3-api.us-geo.objectstorage.softlayer.net/cf-courses-data/CognitiveClass/DA0101EN/auto.csv" df = pd.read_csv(URL, header = None)
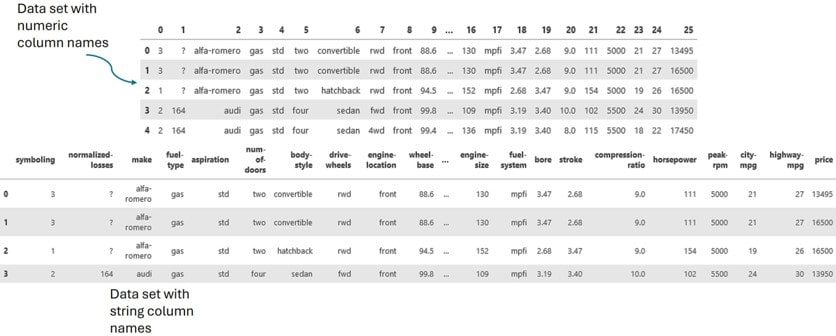
For any data sets, one may update the column (variable) names. For the data stored in the URL, the column names are 0, 1, 2, …, 25. Therefore, one can name the columns with some strings, like
headers = ["symboling", "normalized-losses", "make", "fuel-type", "aspiration", "num-of-doors", "body-style", "drive-wheels", "engine-location", "wheel-base", "length", "width", "height", "curb-weight", "engine-type", "num-of-cylinders", "engine-size", "fuel-system", "bore", "stroke", "compression-ratio", "horsepower", "peak-rpm", "city-mpg", "highway-mpg", "price"] df.columns = headers df
Exporting Data Sets in Python
The data sets in Python can also be imported to diffeent file format. For example
# export as csf file
df.to_csv("data.csv", index = False)
# export as excel file
df.to_excel("data.xlsx", index = False)Instead of importing data set, one can also generate his/her own data set.
before = stats.norm.rvs(scale = 30, loc = 250, size = 100)
after = before + stats.norm.rvs(scale = 5, loc = -1.25, size = 100)
df = pd.DataFrame(
{"Weight_before": before,
"Weight_after": after,
"diff": after-before}
)
df.describe()